










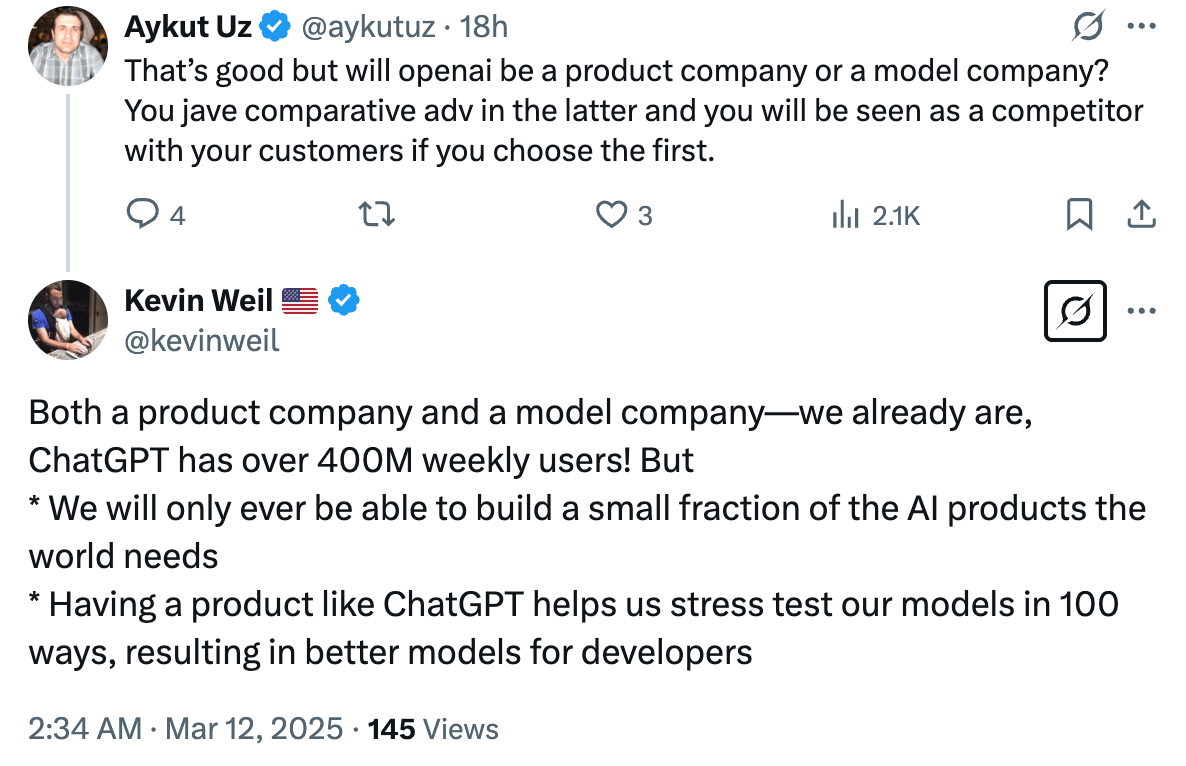












































































![How to Use GA4 to Track Social Media Traffic: 6 Questions, Answers and Insights [VIDEO]](https://www.orbitmedia.com/wp-content/uploads/2023/06/ab-testing.png)
![How Human Behavior Impacts Your Marketing Strategy [Video]](https://contentmarketinginstitute.com/wp-content/uploads/2025/03/human-behavior-impacts-marketing-strategy-cover-600x330.png?#)

![How to Make a Content Calendar You’ll Actually Use [Templates Included]](https://marketinginsidergroup.com/wp-content/uploads/2022/06/content-calendar-templates-2025-300x169.jpg?#)
![Building A Digital PR Strategy: 10 Essential Steps for Beginners [With Examples]](https://buzzsumo.com/wp-content/uploads/2023/09/Building-A-Digital-PR-Strategy-10-Essential-Steps-for-Beginners-With-Examples-bblog-masthead.jpg)


























Python Web Scraper Bypass Cloudflare Protection
I need a Python expert who can provide a solution for scraping data from a website currently protected by Cloudflare. The site is a betting platform (www.racingandsports.com) where I want to collect horse racing results on a daily basis... (Budget: $10 - $30 AUD, Jobs: Data Mining, Python, Selenium Webdriver, Software Architecture, Web Scraping)
I need a Python expert who can provide a solution for scraping data from a website currently protected by Cloudflare. The site is a betting platform (www.racingandsports.com) where I want to collect horse racing results on a daily basis... (Budget: $10 - $30 AUD, Jobs: Data Mining, Python, Selenium Webdriver, Software Architecture, Web Scraping)