






































































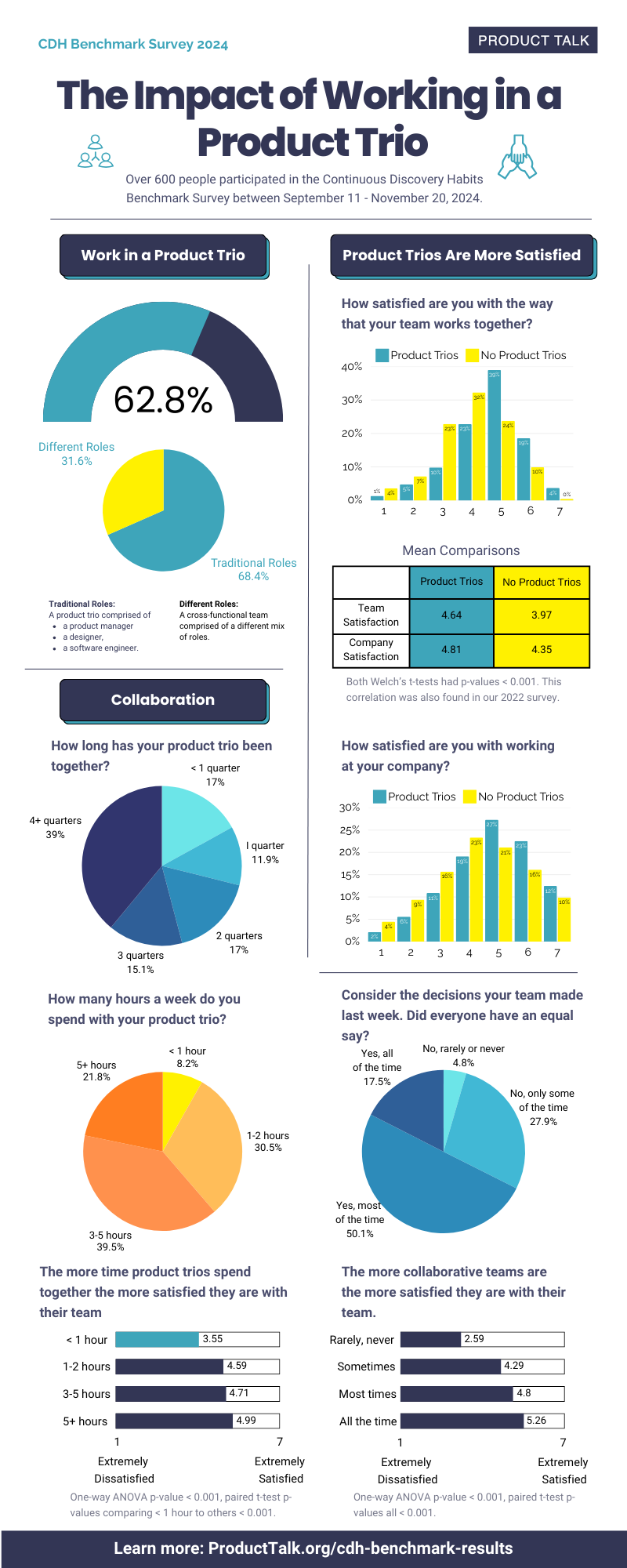


















![Building A Digital PR Strategy: 10 Essential Steps for Beginners [With Examples]](https://buzzsumo.com/wp-content/uploads/2023/09/Building-A-Digital-PR-Strategy-10-Essential-Steps-for-Beginners-With-Examples-bblog-masthead.jpg)



![How Human Behavior Impacts Your Marketing Strategy [Video]](https://contentmarketinginstitute.com/wp-content/uploads/2025/03/human-behavior-impacts-marketing-strategy-cover-600x330.png?#)


![How to Make a Content Calendar You’ll Actually Use [Templates Included]](https://marketinginsidergroup.com/wp-content/uploads/2022/06/content-calendar-templates-2025-300x169.jpg?#)
![How to Use GA4 to Track Social Media Traffic: 6 Questions, Answers and Insights [VIDEO]](https://www.orbitmedia.com/wp-content/uploads/2023/06/ab-testing.png)


















The most innovative companies in artificial intelligence for 2025
The AI industry hit a significant bend in the road toward artificial general intelligence in 2024. Previously, the stunning intelligence gains that led to chatbots such ChatGPT and Claude had come from supersizing models and the data and computing power used to train them. When the progress from massive scaling leveled off, researchers knew they would need a new strategy, beyond training, to keep moving toward AGI models that are broadly smarter than humans. Starting with OpenAI’s pivotal o1 model, researchers began to apply more computing power to the real-time reasoning a model does just after a user prompts it with a problem or question. o1 required more time to produce answers than other models, but its answers were clearly better than those of non-reasoning models. The o1 model rose quickly to the top of the rankings in common benchmark tests, and soon Google DeepMind, Anthropic, DeepSeek and others were training their models for real-time reasoning. The big AI labs would now need even more of the Nvidia GPUs they’d been using for training to support all the real-time reasoning their models would be doing. That’s part of the reason Nvidia saw its stock price rise 171% in 2024. The chip company had been reading the tea leaves and built new features into its GPUs that made them even better suited to real-time inference than before. The result was a new architecture called Blackwell, and new chips called the B100 and B200. Nvidia unveiled the new GPUs in March 2024 and quickly sold its entire 2024 supply to the largest data center operators. Even before the appearance of new reasoning models, some of AI’s hottest companies produced state-of-the-art new AI systems. Google DeepMind broke through with a family of natively multi-modal models called Gemini that understand imagery and audio as well as they do language. Anthropic continued to put intense pressure on OpenAI, and was first to release an AI model that could perform task on a user’s computer. Mistral released impressive new small language models that can run on laptops and even phones with its Ministral 3B and Ministral 8B, as did Microsoft with its Phi-3 and Phi-4 models. And Runway again made its case for the state-of-the-art with its new Gen-3 Alpha video generation models. And all the while a small AI lab in China was quietly developing new AI models, including reasoning models, that would begin sending shockwaves through the AI industry by the end of 2024. DeepSeek—#1 on our list of the most innovative companies in Asia-Pacific—trained state-of-the-art models at far lower cost and with far less GPU power than anyone thought possible. It even showed its work through research papers and by open-sourcing its models. DeepSeek’s breakthroughs caused some angst, but its fresh thinking and openness will likely spur bigger and faster innovations from the world’s top AI companies by this time next year.1. NvidiaFor arming employees with the tools to get their jobs doneLarge-language model makers continue to pour money into realizing the lofty ambitions of their AI systems. But one company is already reaping the rewards. Nvidia kicked off the AI race by providing the computing power with its market-dominating graphics processing units (GPUs). Now, as its customers chase human-level intelligence, its groundbreaking Blackwell processor and platform is ready. For general model training tasks, the Blackwell processor is up to 2.5 times more powerful than its predecessor, the H100, and requires significantly less energy to operate. The largest data center operators and AI labs, including Google, Meta, Microsoft, OpenAI, Tesla and xAI, are buying or planning to buy Blackwell GPUs by the hundreds of thousands.While recent models from China’s DeepSeek and Alibaba have made big strides in wringing cutting-edge AI out of older, less powerful Nvidia GPUs, the company isn’t just cranking out processors and waiting to see what the world does with them. Instead, it’s actively building platforms for everything from drug discovery (Clara for Biopharma) to autonomous vehicles (Drive AGX) to video production (Holoscan) to digital twins (Omniverse). By driving AI progress in an ever-growing array of real-world scenarios, it’s positioning itself for continued growth, even if future models don’t need all the computational muscle they can get.Read more about Nvidia, honored as No. 2 on Fast Company’s list of the World’s 50 Most Innovative Companies of 2025.2. OpenAIFor improving AI by giving it more time to thinkSince 2019, OpenAI has continually improved its models by giving them more training data and computing power. The rest of the industry has followed its lead. Now that researchers are seeing diminishing returns from this scaling strategy, OpenAI needed an alternative route toward its goal of creating AI models that are smarter than humans in most tasks–in other words, models that can reach artificial general intelligence (AGI).The company found it, and the resulting

The AI industry hit a significant bend in the road toward artificial general intelligence in 2024. Previously, the stunning intelligence gains that led to chatbots such ChatGPT and Claude had come from supersizing models and the data and computing power used to train them. When the progress from massive scaling leveled off, researchers knew they would need a new strategy, beyond training, to keep moving toward AGI models that are broadly smarter than humans.
Starting with OpenAI’s pivotal o1 model, researchers began to apply more computing power to the real-time reasoning a model does just after a user prompts it with a problem or question. o1 required more time to produce answers than other models, but its answers were clearly better than those of non-reasoning models. The o1 model rose quickly to the top of the rankings in common benchmark tests, and soon Google DeepMind, Anthropic, DeepSeek and others were training their models for real-time reasoning.
The big AI labs would now need even more of the Nvidia GPUs they’d been using for training to support all the real-time reasoning their models would be doing. That’s part of the reason Nvidia saw its stock price rise 171% in 2024. The chip company had been reading the tea leaves and built new features into its GPUs that made them even better suited to real-time inference than before. The result was a new architecture called Blackwell, and new chips called the B100 and B200. Nvidia unveiled the new GPUs in March 2024 and quickly sold its entire 2024 supply to the largest data center operators.
Even before the appearance of new reasoning models, some of AI’s hottest companies produced state-of-the-art new AI systems. Google DeepMind broke through with a family of natively multi-modal models called Gemini that understand imagery and audio as well as they do language. Anthropic continued to put intense pressure on OpenAI, and was first to release an AI model that could perform task on a user’s computer. Mistral released impressive new small language models that can run on laptops and even phones with its Ministral 3B and Ministral 8B, as did Microsoft with its Phi-3 and Phi-4 models. And Runway again made its case for the state-of-the-art with its new Gen-3 Alpha video generation models.
And all the while a small AI lab in China was quietly developing new AI models, including reasoning models, that would begin sending shockwaves through the AI industry by the end of 2024. DeepSeek—#1 on our list of the most innovative companies in Asia-Pacific—trained state-of-the-art models at far lower cost and with far less GPU power than anyone thought possible. It even showed its work through research papers and by open-sourcing its models. DeepSeek’s breakthroughs caused some angst, but its fresh thinking and openness will likely spur bigger and faster innovations from the world’s top AI companies by this time next year.
1. Nvidia
For arming employees with the tools to get their jobs done
Large-language model makers continue to pour money into realizing the lofty ambitions of their AI systems. But one company is already reaping the rewards. Nvidia kicked off the AI race by providing the computing power with its market-dominating graphics processing units (GPUs). Now, as its customers chase human-level intelligence, its groundbreaking Blackwell processor and platform is ready.
For general model training tasks, the Blackwell processor is up to 2.5 times more powerful than its predecessor, the H100, and requires significantly less energy to operate. The largest data center operators and AI labs, including Google, Meta, Microsoft, OpenAI, Tesla and xAI, are buying or planning to buy Blackwell GPUs by the hundreds of thousands.
While recent models from China’s DeepSeek and Alibaba have made big strides in wringing cutting-edge AI out of older, less powerful Nvidia GPUs, the company isn’t just cranking out processors and waiting to see what the world does with them. Instead, it’s actively building platforms for everything from drug discovery (Clara for Biopharma) to autonomous vehicles (Drive AGX) to video production (Holoscan) to digital twins (Omniverse). By driving AI progress in an ever-growing array of real-world scenarios, it’s positioning itself for continued growth, even if future models don’t need all the computational muscle they can get.
Read more about Nvidia, honored as No. 2 on Fast Company’s list of the World’s 50 Most Innovative Companies of 2025.
2. OpenAI
For improving AI by giving it more time to think
Since 2019, OpenAI has continually improved its models by giving them more training data and computing power. The rest of the industry has followed its lead. Now that researchers are seeing diminishing returns from this scaling strategy, OpenAI needed an alternative route toward its goal of creating AI models that are smarter than humans in most tasks–in other words, models that can reach artificial general intelligence (AGI).
The company found it, and the resulting model is called o1. Instead of scaling up training data and compute time while the model is pre-trained, OpenAI researchers built o1 to spend more time and computing power at inference, when the model is deployed and answering user prompts. While doing this, the model collects and remembers contextual data, both from the user and from relevant data sources. It takes a trial-and-error approach to figuring out the best route to an answer. The model generates PhD-level answers to complex questions, landing it on top of performance benchmark rankings.
OpenAI o1 “experimental” and “mini” versions are available to ChatGPT Plus users. The company offers a new service called ChatGPT Pro that provides unlimited access to o1 proper for $200 per month. In December of 2024 OpenAI announced o1’s successor, o3, and in February 2025 it gave paid users access to o3-mini, a smaller, faster version that excels in science, math, and coding. The biggest impact of OpenAI’s new reasoning models is proving to the industry that scaling up computing at inference time may be a viable path to making new intelligence breakthroughs on the way to AGI.
3. Google DeepMind
For delivering a truly multi-modal AI model
The foundational research in AI model architecture and model training that led to the chatbots of today happened at Google in the late 2010s. The search giant developed a large language model-powered chatbot long before ChatGPT, but, as the story goes, it hesitated to expose the technology to the public because of concerns over safety, privacy, and legal risks. That hesitation put Google behind in the AI race that ensued with the launch of ChatGPT.
The release of Google DeepMind’s Gemini 2.0 in 2024 marked the moment when Google officially caught up. Gemini 2.0 is the first mass market AI model that is natively “multimodal,” meaning that it can process and generate images, video, audio, and computer code the same way it does text. This makes it possible for the model to watch a video clip, or live video from a phone camera, and quickly analyze and reason about it.
The Gemini model is also notable for being able to control other Google services such as Maps and Search. This is Google beginning to flex–combining its AI research with its legacy information and productivity tools. Gemini is one of the first AI models capable of working autonomously and reasoning its way through complex problems on the behalf of the user. The Gemini 2.0 Flash Thinking Experimental model even shows the user the thought process it used to reach an answer. And in December, Google showed off Project Mariner, a Gemini-based agentic AI feature designed to perform tasks such as online grocery shopping on behalf of the user.
4. Anthropic
For imbuing Claude with the ability to use a computer
Generative AI has so far been used mainly for a few tasks: writing and summarizing text as well as generating images. The next step is making large language models reason and use tools. Anthropic’s “Computer Use” model gave us our first look into that future.
Starting with 2024’s Claude 3.5 Sonnet, Anthropic’s model can perceive what’s happening on the user’s screen, including internet content. It can operate a cursor, click buttons, and type in text. In a video, a Claude researcher demonstrated how Claude can fill out a form based on information available at the websites open in the browser tabs. It can complete tasks such as building a personal website or sorting the logistics of a day trip. It’s wild to watch the AI work, clicking open new tabs, running searches, and filling in data fields.
Right now the model runs slowly and doesn’t always get the right answer, but that’s likely to change quickly as Anthropic finds and fixes the model’s pitfalls. Google’s aforementioned Project Mariner followed Anthropic’s lead in December, and OpenAI introduced its own computer use model, Operator, in January 2025. In February 2025, Anthropic moved on to its next major iteration of Claude, Claude 3.7 Sonnet, a larger model that can automatically switch into reasoning mode for hard questions.
5. Microsoft
For pushing the state-of-the-art in small language models
The development of Microsoft’s Phi models started out with a question posed by the company’s researchers in 2023: “How small can we make a model that shows signs of emerging intelligence?” This turns out to be an important moment in the evolution of “small language models,” or models that perform well in scenarios where memory, processing power, or connectivity are limited, and response speed is important.
During 2024, Microsoft released two generations of small models that exhibited reasoning and logic capabilities that hadn’t been explicitly trained into them. In April the company released a series of Phi-3 models that excel in language, reasoning, coding, and math benchmarks–probably owing to the fact that Microsoft trained them using synthetic data generated by much larger and more capable LLMs. People downloaded variants of the open-source Phi-3 more than 4.5 million times on HuggingFace during 2024.
In late 2024, Microsoft released its Phi-4 small language models, which improved on the Phi-3 models in reasoning-focused tasks and even outperformed OpenAI’s GPT-4o on the GPQA (scientific questions) and MATH benchmarks. Microsoft released the model under an open-source and open-weights license, so developers can use it to develop edge models or apps that run on phones or laptops. In less than a month, Phi-4 was downloaded 375,000 times on HuggingFace.
6. Amazon
For building a cost-effective rival to Nvidia’s GPU
Amazon AWS recently released a new version of its Tranium processor for AI, called Trainium2, which—in some settings—could challenge the dominance of Nvidia GPUs. The Trainium2 chip is built to supply the massive computing power used in training the largest generative AI models, and for inference time work after the model has been deployed. AWS says Trainium is 30% to 40% more cost-effective in jobs normally done by GPUs.
Trainium2 cures the power and software integration deficiencies seen in the first Trainium chip, says Dylan Patel of SemiAnalysis, and puts Amazon “on a path” toward catching up to Nvidia. (Note that AWS itself remains very reliant on NVIDIA for GPUs.) Unseating Nvidia is difficult because customers get locked in to building on top of Nvidia’s CUDA software layer, which lets researchers control how their models use the chip’s resources. Amazon offers its own kernel control software layer called Neuron Kernel Interface (NKI), which, like CUDA, gives researchers granular control over how the chip kernels work together.
Patel points out that Trainium2 is still untested at scale. AWS is now building a server cluster with 400,000 Trainium2 chips for Anthropic, which could teach it a lot about making its AI chips work well together in big numbers.
7. Arm
For making AI data centers more cost effective and efficient
The British semiconductor designer Arm has long provided the tech industry with the architecture used in chips that power small devices such as phones, sensors, and IoT hardware. This takes on new importance as a new era arrives in which edge device chips will run AI models. But data centers will play a huge role in this evolution as well, often handling some or all of the heaviest AI processing and delivering the results down to the edge device.
As data centers expand around the world, the amount of electrical power they use will become a pressing consideration. That’s part of the reason Arm’s latest Neoverse CPU architecture focuses on efficiency. It offers a 50% performance improvement over earlier generations, and 20% better performance per watt than processors using competing x86 architectures, the company says.
Arm says that Amazon, Microsoft, Google, and Oracle have all now adopted Arm Neoverse for both general-purpose computing and CPU-based AI inference and training. For example, in 2024 Micerosoft announced its first custom silicon built for the cloud, the Cobalt 100 processor, was built on Arm Neoverse. Some of the largest AI data centers will rely on NVIDIA’s Grace Hopper Superchip, which contains a Hopper GPU and a Grace CPU that uses Neoverse. Arm is reportedly planning to launch its own CPU this year, with Meta as one of its first customers.
8. Gretel
For feeding the generative AI boom with synthetic data
Over the past year, AI companies have seen diminishing returns from training their models with ever larger amounts of data scraped from the web. They’ve begun focusing less on the quantity of their training data, and more on its quality. That’s why the they’re are spending more and more on non-public and specialty content that the license from publisher partners. AI researchers also must fill gaps or blind spots within their human-generated or human-annotated training data. For this they’ve increasingly turned to synthetic training data generated by special AI models.
Gretel gained a higher profile during 2024 by specializing in creating and curating synthetic training data. The company announced the general availability of its flagship product, Gretel Navigator, which lets developers use natural language or SQL prompts to create, augment, edit, and curate synthetic training datasets, or their fine-tuning and testing datasets. The platform has already attracted a community of more than 150,000 developers who have synthesized more than 350 billion pieces of training data.
Other industry players have taken notice. Gretel partnered with Google to make its synthetic training data easily available to Google Cloud customers. The company announced a similar partnership with Databricks in June, which allows that company’s enterprise customers to access synthetic training data for their models running within the Databricks cloud.
9. Mistral AI
For creating small AI models that run in laptops and phones
Mistral AI, France’s entry into the generative AI race, has constantly put pressure on OpenAI, Anthropic, and Google at the leading edge of frontier AI model development. Mistral AI released a string of new models containing significant technological advances in 2024, and demonstrated rapid growth in its business, both through direct marketing of its APIs and through strategic partnerships.
Early in the year the company produced a pair of open-source models called Mixtral, notable for its innovative use of the “mixture of experts” architecture, in which only a specialized subset of the model’s parameters are put in play to handle a query, improving efficiency. In July 2024 Mistral announced Mistral Large 2, which, at 123 billion parameters, showed significant improvements in code generation, maths, reasoning, and function calling. The French company also released Ministral 3B and Ministral 8B–both of which are smaller models that can run in laptops or phones and store about 50 text pages of context information provided by the user.
Mistral has seen success in Europe by marketing itself as a low-cost and flexible alternative to U.S. AI companies like OpenAI. It also continued its expansion into the U.S. enterprise market during 2024. In June, the company raised a $640 million funding round, led by the venture capital firm General Catalyst. The round increased Mistral’s valuation to roughly $6.2 billion.
10. Fireworks AI
For bringing a plug-and-play model to AI development and deployment
Fireworks provides a custom runtime environment that removes some of the considerable engineering work typically associated with building infrastructure for AI deployments. Using the Fireworks platform, enterprises can plug in any of more than 100 AI models, then customize and fine-tune them for their specific use cases.
The company introduced new products during 2024 that will equip it to ride some important waves in the AI industry. For one, developers have become more concerned about how quickly AI-powered models and apps respond to user requests. Fireworks debuted its FireAttentionV2, an optimization and quantization software that speeds up the work of models and reduces network latency. Secondly, AI systems are increasingly not single models but “pipelines” that call different models and tools using APIs. A new FireFunction V2 software works as an orchestrator of all the components in these increasingly complex systems, especially as enterprises launch more autonomous AI apps.
Fireworks says it saw a 600% rise in revenue growth in 2024. Its customer base includes Verizon, DoorDash, Uber, Quora, Upwork, and other known names.
11. Snorkel AI
For helping businesses prepare their data for use in AI models
Enterprises have learned that their AI systems are only as good as their data. And Snorkel AI has made an impressive business out of helping enterprises get their proprietary data ready for use in AI models. The company’s Snorkel Flow AI data development platform gives companies a cost-efficient way to label and curate their proprietary data so that it can be used to customize and evaluate AI models for their unique business purposes.
In 2024, Snorkel added support for images, letting companies train multimodal AI models and image generators using their own proprietary images. It also added retrieval augmented generation (RAG) to its platform, which allowed its customers to retrieve only the most relevant chunks of information from long documents–such as proprietary knowledge base content–for use in training the AI. Snorkel Custom, a higher-touch new service level, puts the company’s machine learning experts to work on projects directly with the customer.
Snorkel says its year-over-year annual bookings doubled during 2024, with triple-digit growth in annual bookings in each of the last three years. Six of the largest banks now use Snorkel Flow, the company says, as well as brands such as Chubb, Wayfair, and Experian.
12. CalypsoAI
For letting companies see the logic behind AI decisions in real time
As AI becomes more instrumental in critical decision-making processes, enterprises are looking for ways to gain more visibility into the workings of the models. That goes double for companies in regulated industries that must constantly watch for bias and other unintended outputs. CalypsoAI was among the first to recognize this emerging need, and it quickly responded with enhanced explainability features in its AI infrastructure platform.
What’s surprising about Calypso is the reach of its observability technology. In 2024 the company launched its AI Security Platform, which protects enterprise data by securing, auditing, and monitoring all active generative AI models a company may be using, regardless of the model vendor or whether the model is hosted internally or externally. Calypso also introduced new visualization tools that allow users to see the logic behind AI decisions in real time.
The market is responding to Calypso’s shift toward AI observability. The company says it saw a 10x inclease in its revenues during 2024, and expects its revenues to grow by another 5x in 2025.
13. Galileo
For creating an AI model that can spot hallucinations in other models
On the whole, AI systems hallucinate facts and show biases less than they did a year ago. But they’re still prone to these issues, a worrisome situation for any business using AI—especially those in regulated industries such as healthcare and banking. AI development teams use Galileo’s AI platform to measure, optimize, and monitor the accuracy of their models and apps.
In early 2024, after two years of research, Galileo released a suite of evaluation models called Luna that are trained to recognize harmful outputs. The models enable Galileo’s platform to quickly scrutinize and score the work of an LLM while it’s in the process of stringing together the tokens that will form its response. This takes the system about only about 200 milliseconds, leaving time to flag and prevent the AI’s output from being seen by a user. It’s possible to use a standard LLM to perform this task, but it’s expensive. Galileo’s purpose-built models are more accurate, more cost-efficient, and, importantly, faster.
Galileo says it quadrupled its customer count in 2024, and that it counts Twilio, Reddit, Chegg, Comcast, and JP Morgan Chase as clients. The startup also raised a $68 million funding round from investors such as HuggingFace CEO Clement Delangue.
14. Runaway
For pairing with Lionsgate to create Hollywood-ready AI tools
One of the great hopes—and fears—about AI is that it’ll soon be able to generate video that’s good enough to change the art and economics of filmmaking forever. The technology took some large steps in the direction of that future during 2024, and one of the main companies pushing the state-of-the-art is the New York-based video generation startup Runway. When the company released its new Gen-3 Alpha model in June 2024, many in the AI community took to X to croon about the much improved believability of the generated video.
Runway also made major improvements to its tools for controlling the look of AI video. The model was trained on both images and video, and can create video based on either text or image inputs. The company followed up with Gen-3 Alpha Turbo, a more cost-efficient and speedy version of Gen-3.
Hollywood has been watching generative AI’s progress closely, and Runway says its now begun producing custom versions of its models for entertainment industry players. It entered into a formal partnership with one such player, Lionsgate Studios, in September 2024. Runway built a custom model for the production company and trained it on Lionsgate’s film catalog. Runway says the model is meant to help Lionsgate’s filmmakers, directors and other creatives “augment” their work while “saving time, money and resources.” Runway believes its arrangement with Lionsgate could serve as a template for similar deals with other production companies.
15. Cerebras Systems
For taking a bigger-is-better approach to AI chips
AI systems, especially large frontier models, require tremendous amounts of computing power to run at scale. That means that thousands or millions of chips must be wired together to share the workload, but the network connections between the chips can slow things down. Cerebras Systems’ technology is designed to reap the speed and efficiency benefits of putting a lot of computing power in one really big chip.
The company’s latest WS-3 (third-generation Wafer Scale Engine) chip, for example, is the size of a dinner plate at 814 square millimeters, 56 times larger than NVIDIA’s market-leading H100 chips. The chip packs an astonishing 4 trillion transistors, offers 44 gigabits of memory, and can be clustered together to form supercomputers, such as Condor Galaxy, a “constellation” of interconnected supercomputers Cerebras is developing with its biggest customer, UAE-based AI and cloud computing company G42.
So far Cerebras has found a sweet spot in large research organizations such as Mayo Clinic, Sandia National Laboratories, Lawrence Livermore, and the Los Alamos National Laboratory. The company filed papers for an IPO in September 2024. The prospectus says the company’s sales more than tripled to $78.7 million in 2023 and climbed to $136.4 million in the first half of 2024.
Explore the full 2025 list of Fast Company’s Most Innovative Companies, 609 organizations that are reshaping industries and culture. We’ve selected the companies making the biggest impact across 58 categories, including advertising, applied AI, biotech, retail, sustainability, and more.


