










































































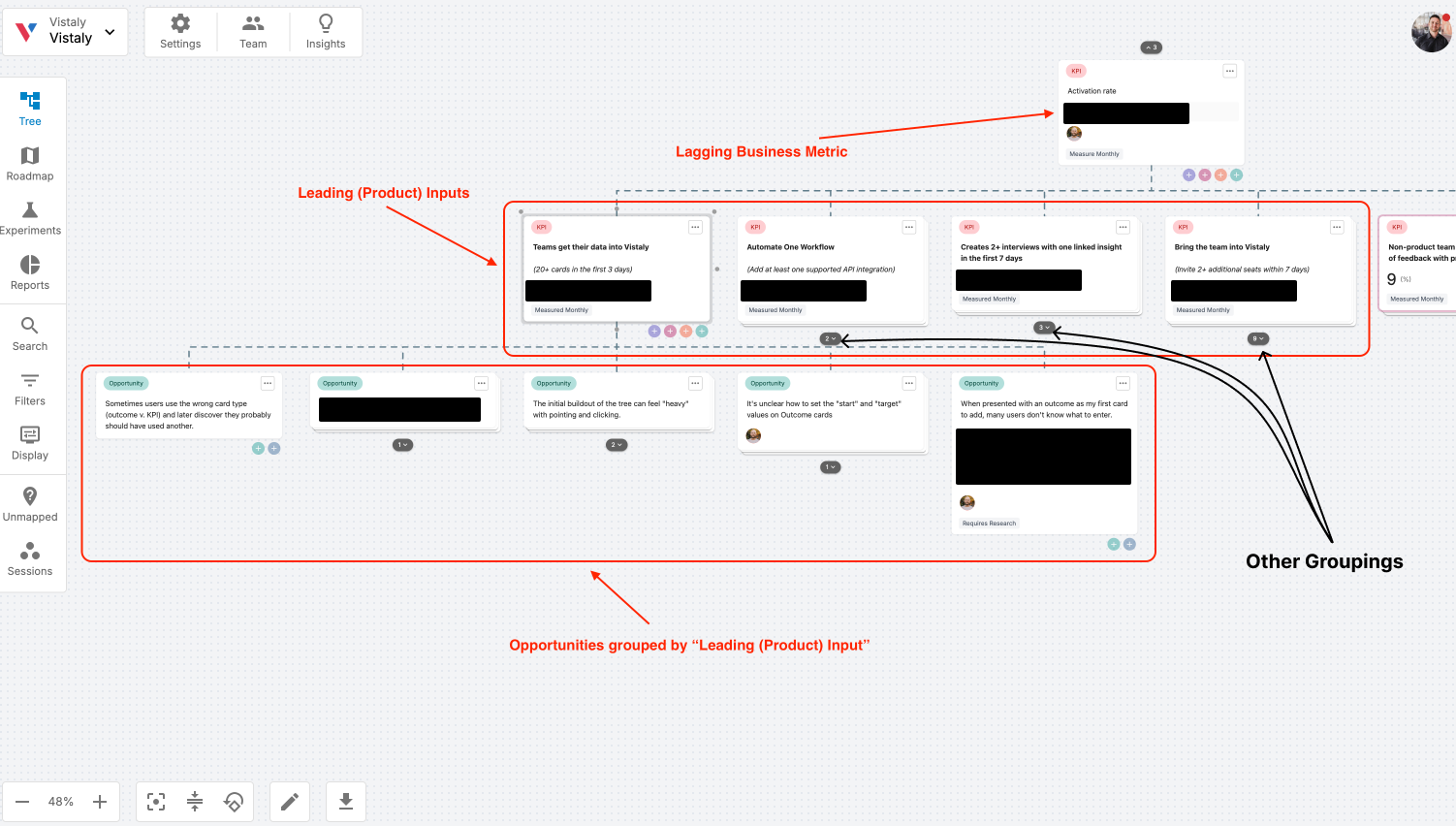











![How One Brand Solved the Marketing Attribution Puzzle [Video]](https://contentmarketinginstitute.com/wp-content/uploads/2025/03/marketing-attribution-model-600x338.png?#)
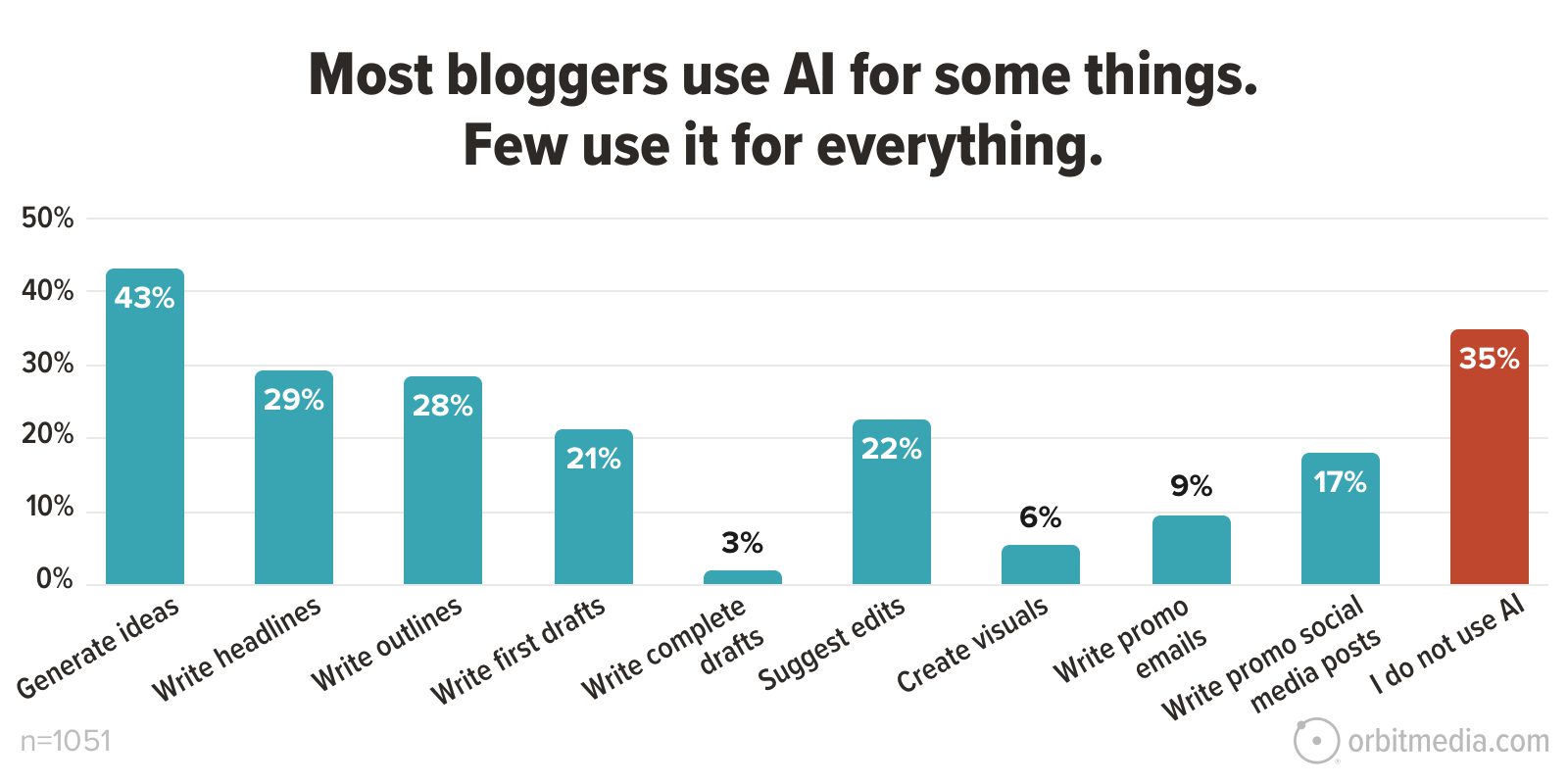
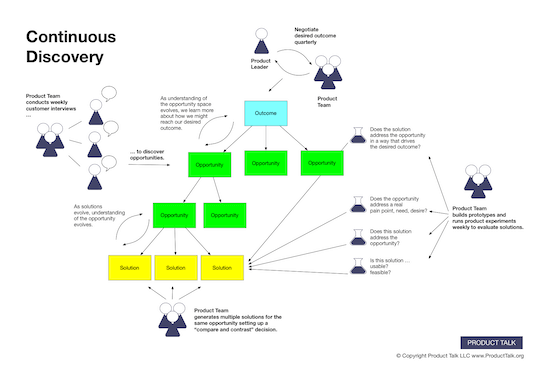
![Building A Digital PR Strategy: 10 Essential Steps for Beginners [With Examples]](https://buzzsumo.com/wp-content/uploads/2023/09/Building-A-Digital-PR-Strategy-10-Essential-Steps-for-Beginners-With-Examples-bblog-masthead.jpg)










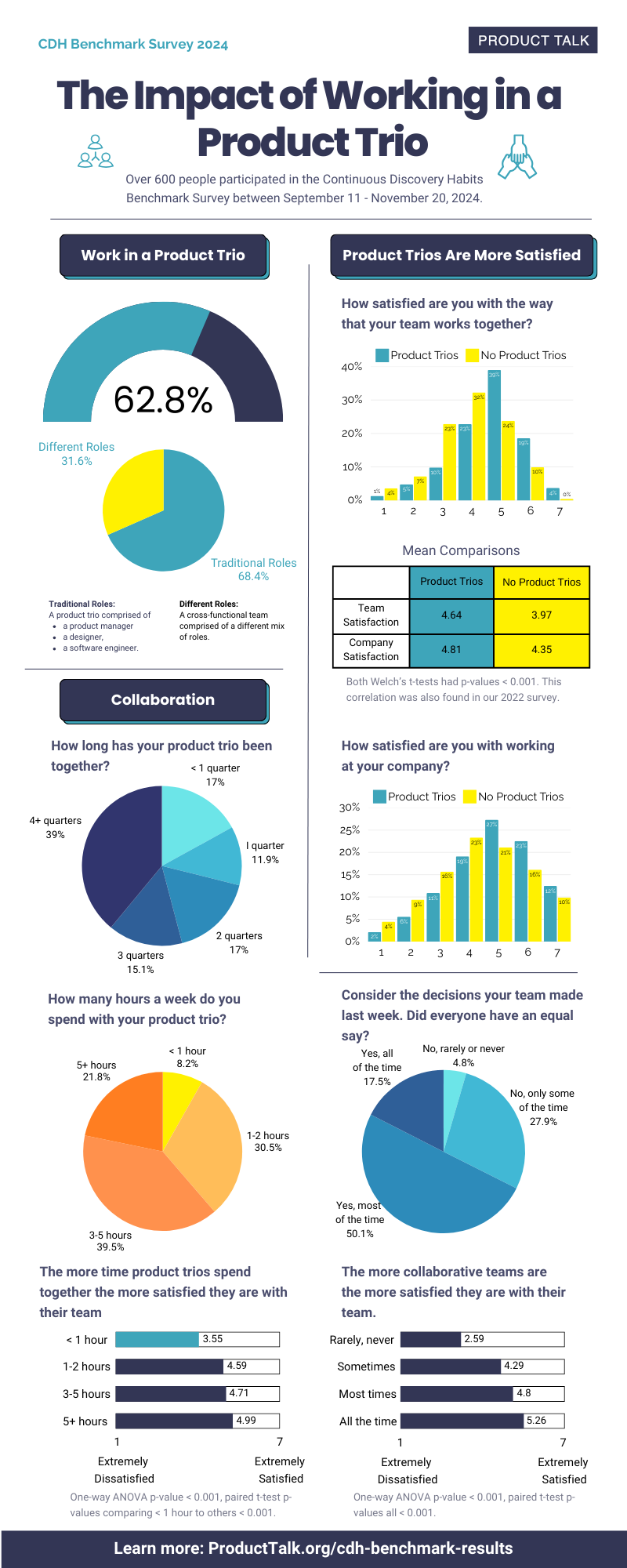
![How to Use GA4 to Track Social Media Traffic: 6 Questions, Answers and Insights [VIDEO]](https://www.orbitmedia.com/wp-content/uploads/2023/06/ab-testing.png)



![[HYBRID] ?? Graphic Designer](https://a5.behance.net/cbf14bc4db9a71317196ed0ed346987c1adde3bb/img/site/generic-share.png)









ChatGPT Just Got a Huge Image-Generation Upgrade
More realism, better text, improved consistency.

OpenAI has significantly leveled up the image generating capabilities of ChatGPT, adding the update as part of the GPT-4o model introduced last May. The new and improved AI generator is rolling out now for all ChatGPT users, across paid plans and the free tier (though free users are more restricted in how much they can use it).
It's been possible to generate images through the ChatGPT interface for a while now, though behind the scenes the work was farmed out to the DALL-E 3 image model. Now, everything will be handled by GPT-4o, for a more consistent and native experience.
There are lots of improvements here, which cover some of the areas that AI image creator tools have typically struggled with: rendering text, keeping characters consistent across pictures, and drawing diagrams. OpenAI says you can now expect more "precise, accurate, [and] photorealistic" results from your prompts.
More realistic and accurate images

Images made with AI often come with an artificial sheen that tells you they've been dreamt up by algorithms, and that should be less obvious with GPT-4o images. One of the demo pictures shown off by OpenAI has a woman writing on a whiteboard, with a view reflected in it—all pretty life-like, though note the small caption at the bottom that tells you this was the best of eight attempts ChatGPT had at the prompt.
The AI art users create should also stick more closely to the prompts given, OpenAI says. So, if you want specific objects in specific places, or you need people in certain positions, then these instructions will apparently be carried out more faithfully. One of the more impressive example images shows a four-panel comic strip rendered by ChatGPT, without any obvious errors or inconsistencies.
I tried to get ChatGPT to turn an Austen novel into a comic strip, and produce a photorealistic image of a stately home with a garden, and the results were impressive—if not quite perfect. They're certainly significantly better than the images ChatGPT was previously producing, although the rendering takes longer to complete (typically minutes rather than seconds).
Text and diagrams are vastly improved

Trying to get AI to render text and diagrams accurately has long been a challenge: The way these tools are built means they're much better at inventing and remixing the images they've been trained on, rather than reproducing an exact copy of the alphabet or a series of rectangles and arrows.
The new GPT-4o model can render text and diagrams to a high level of detail and accuracy, so you shouldn't see as many strange mistakes and inconsistencies. OpenAI's showreel included a menu, an invitation, a boarding pass, and a diagram explaining Newton's prism experiment, all generated from a single text prompt.
When I asked ChatGPT to produce an infographic explaining DNA in simple terms, and a book cover with a specified title and author, it followed the brief pretty exactly—the graphic was basic but accurate (as per the prompt), and the book cover looked like something you might see in a store. Just as importantly, there were no weird artifacts or inconsistencies in the images.
Consistency and editing

I've written before about the limitations of ChatGPT image editing, and this is another area that's been upgraded. It's now easier to keep characters and scenes consistent between images, to only tweak parts of a picture and leave the rest untouched, and to build up different layers of an image. You can even create transparent backgrounds, if needed, or specify colors using hex codes.
Other improvements come in the way ChatGPT can accept and remix your own images, and incorporate other information (from the web and its training data): So one of the demo OpenAI pictures was built from the prompt "make a visual infographic describing why SF is so foggy" and ChatGPT did just that (well, best of three).
In my own tests, I found ChatGPT much better at editing images, and pretty competent at remixing pictures in different styles. It still struggles to some extent keeping consistency between images—especially with complex objects and characters. It's definitely better than it was at this, but there's still a tendency to overdo the edits, making the AI less useful for tweaking images or making a series of several images that need to match.
Copyright and safety issues

As with any generative AI announcement, issues around copyright, misuse, and energy demands are once again brought to mind. OpenAI is on record as saying it's impossible to build these tools without training on copyrighted images, though it has recently started signing content deals with providers such as Shutterstock. Brad Lightcap, OpenAI’s chief operating officer, told the Wall Street Journal that the GPT-4o image generator will reject requests to mimic the work of any living artist.
When it comes to safety, OpenAI says generated images all come with C2PA metadata to identify them as AI-generated—though this metadata can be easily removed with something as simple as a screenshot. The AI generator is also built to rebuff any attempts to create "child sexual abuse materials and sexual deepfakes" OpenAI says, as well as other prompts that violate its content policies.
This is clearly a major step forward for AI images: The upgraded technology is genuinely jaw-dropping at times, and a lot of the tell-tale signs of AI and the errors made by the tech are vanishing. It does raise some big questions about the future we're all barreling towards though, one where fakes are so easily made, where creative work is done by robots rather than people—and where we collectively lose our ability to sketch a picture, craft a sentence, or write a line of code. And then how will generative AI find more training data?

